데이터 분석 스터디를 하면서 기본적인 사용방식, 시각화 방식을 익혔다.
이를 적용하는 연습을 해보기로 하였다.
이번에 연습해볼 데이터는 2016년부터 2021년까지 인구 변화를 파악하는 것이다.
import pandas as pd
import matplotlib.pyplot as plt
일단 기본적으로 import 해야 하는 것들은 해주었다.
중간에 필요한 것들은 아래에서 진행할 예정이다.
전국 인구의 변화
먼저 전국 인구 변화가 궁금했다.
file=pd.read_excel('201612_202112_연령별인구현황_연간.xlsx',skiprows=3,index_col='행정기관',usecols='B,C,AP,CC,DP,FC,GP')
file.iloc[0]=file.iloc[0].str.replace(',','').astype(int)
file
그래서 파일을 읽어들인 다음에 행정기관 row를 header로 만들어주었다.
그리고 년도별 인구 현황을 작업하였는데 연도별 추출이 제대로 되지 않아 해당 column을 직접 설정해서 진행하였다.
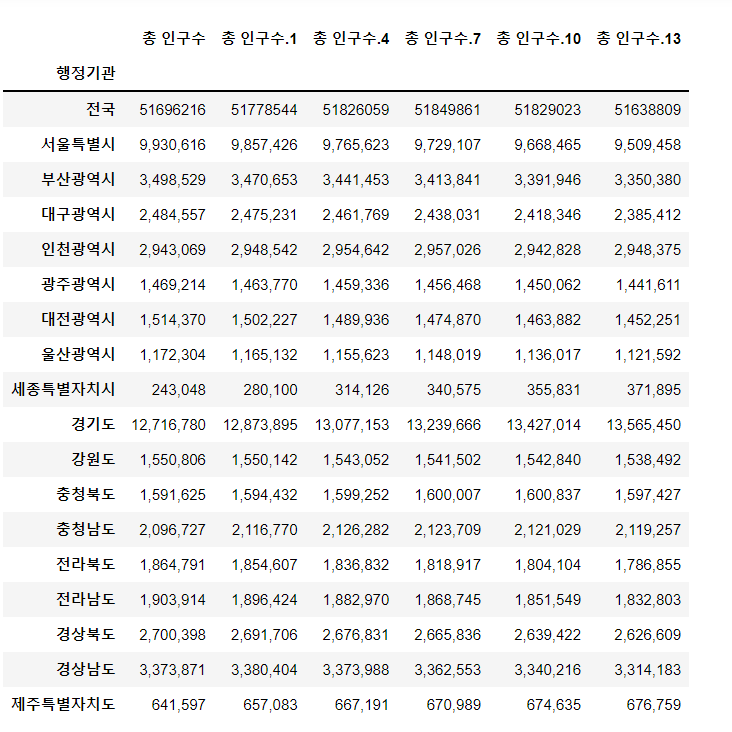
결과는 정상적으로 출력되었다.
그리고 전국 데이터에 대한 꺾은선 그래프 처리를 위해 전국 데이터에 있는 ',' 표시 역시 제거해주는 작업을 해주었다.
file.columns=[2016,2017,2018,2019,2020,2021]
file
그러나 같은 이름의 탓인지 연도 구분이 되지 않았다.
그래서 column이름을 직접 바꾸기로 결정.
16년도부터 21년도이기에 적은 개수의 column으로 직접 리스트에 넣어서 만들어주었다.

그럼 헤더의 총인구수.1 이런 표시가 연도로 변경된 것을 확인할 수 있다.
all=file.iloc[0]
all
다음 과정에서 바로 변화 그래프를 그리고 싶었지만, 처리가 안되는 관계로 첫번째 row를 뽑아서 all이라는 변수에 넣어주었다.

그래서 정상적으로 값이 들어온 것을 확인하고 이제 그릴 준비를 해보자
import matplotlib
matplotlib.rcParams['font.family']='Malgun Gothic'#Windows
#matplotlib.rcParams['font.family']='HYGungSo-Bold'#Windows
matplotlib.rcParams['font.size']=15 #글자 크기
matplotlib.rcParams['axes.unicode_minus']=False # 한글 폰트 사용시 마이너스 글자가 깨지는 현상을 해결
변화 그래프를 그릴 때 한글로 하면 글자가 깨지는 현상이 발생할 수 있는데 이를 방지하는 작업을 해주었다.
맑은 고딕으로 포늩를 설정하고 크기, 그리고 한글폰트 사용시 깨지는 현상을 False로 처리해주었다.
plt.suptitle('전국 인구 변화')
plt.plot(all,color='red',marker='o')
가장 보기 쉬운 형태로 보자
그래프 이름은 전국 인구 변화이고
그래프에 넣은 데이터는 all 데이터, 색은 빨간색, 원형마커로 좀 더 명확히 표시해주었다.

전국 인구 변화를 보니 19년도까지 인구가 증가하다가 20년 조금 감소하였다.
2021년에는 2016년보다 더 적은 인구로 굉장히 감소한 것을 확인할 수 있었다.
남성 인구의 변화
그럼 어디서 큰 변화가 일어났을까?
남녀를 동시에 그리면 좋겠지만 일단 먼저 남성 인구를 알아보기로 하였다.
file_m=pd.read_excel('201612_202112_연령별인구현황_연간.xlsx',skiprows=3,index_col='행정기관',usecols='B,P,BC,CP,EC,FP,HC')
file_m.iloc[0]=file_m.iloc[0].str.replace(',','').astype(int)
file_m
전국인구와 마찬가지로 엑셀에서 해당 셀만 불러오기로 하였다.
인구 수에서 나오는 ','표시도 제거해서 file_m이라는 변수에 넣어주었다.

전국 데이터를 불러왔다.
file_m.columns=[2016,2017,2018,2019,2020,2021]
file_m
마찬가지로 연도별로 표시되도록 column명을 변경해준 뒤

all_m=file_m.iloc[0]
all_m
전국 row에 있는 데이터만 넣어준 후
plt.title('남성 인구의 변화')
plt.plot(all_m,color='blue',marker='o')
앞에것과 같이 title만 변경해준 뒤 파란색 선으로 그려주게 되면
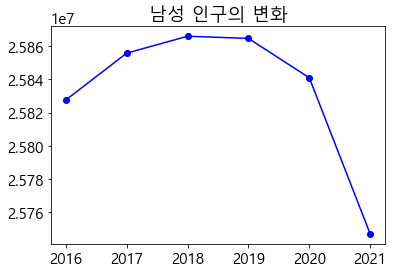
남성 인구도 전국 인구와 비슷한 형태의 모양을 띄는 것을 확인할 수 있다.
여성 인구의 변화
file_w=pd.read_excel('201612_202112_연령별인구현황_연간.xlsx',skiprows=3,index_col='행정기관',usecols='B,AC,BP,DC,EP,GC,HP')
file_w.iloc[0]=file_w.iloc[0].str.replace(',','').astype(int)
file_w
여성 인구 역시 그려나가는 방식은 남성 인구와 같다.
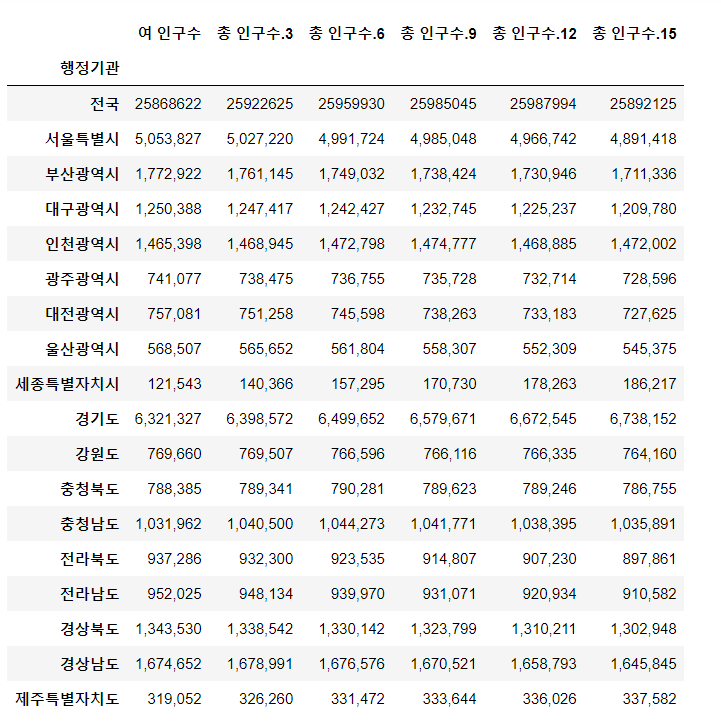
이렇게 전국 데이터를 확인할 수 있고 여기서 전국 데이터만 살펴보자
file_w.columns=[2016,2017,2018,2019,2020,2021]
file_w
일단 여기 헤더도 연도로 다 바꿔주고
all_w=file_w.iloc[0]
all_w
전국 데이터만 뽑아준다.
plt.title('여성 인구의 변화')
plt.plot(all_w,color='pink',marker='o')
여성인구의 변화라는 title로 분홍색으로 그래프를 그려주게 되면

여성은 20년도까지 증가하다가 21년도에 줄어든 것을 확인할 수 있다.
이번 포스팅에서는 전국 남여 인구, 남성인구, 여성인구를 살펴보았다.
다음 포스팅에서는 나이대별로 비교를 해보려고 한다.
이렇게 직접 그려보면 인구 동향도 확실히 알 수 있을 것이고 이 과정에서 여러가지 처리 및 시각화 방식도 익힐 수 있을 것이라고 본다.